1. 사이킷런
사이킷런(scikit-learn)은 파이썬(Python)으로 작성된 오픈소스 머신러닝 라이브러리로, 데이터 분석과 예측 모델 구축을 위해 널리 사용됩니다. 간단하고 일관된 인터페이스를 제공하며, 지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning) 알고리즘을 모두 지원합니다. 주로 분류(Classification), 회귀(Regression), 클러스터링(Clustering), 차원 축소(Dimensionality Reduction), 모델 선택(Model Selection), 전처리(Preprocessing)와 같은 다양한 작업을 수행할 수 있습니다. 사이킷런은 효율적인 수치 계산이 가능하며, 다양한 머신러닝 알고리즘을 손쉽게 사용할 수 있는 API를 제공합니다. 따라서 사이킷런은 데이터 과학과 인공지능 프로젝트에서 가장 많이 사용되는 라이브러리 중 하나입니다.
https://scikit-learn.org/stable/
scikit-learn: machine learning in Python — scikit-learn 1.6.1 documentation
Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning. Algorithms: Grid search, cross validation, metrics, and more...
scikit-learn.org
2. Iris 데이터셋
아이리스(Iris) 데이터셋은 머신러닝과 통계학에서 가장 널리 사용되는 대표적인 샘플 데이터셋입니다. 이 데이터셋은 붓꽃(Iris)의 세 가지 품종(Setosa, Versicolor, Virginica)에 대한 정보를 포함하고 있습니다. 각 품종별로 꽃받침(Sepal)의 길이와 너비, 꽃잎(Petal)의 길이와 너비로 이루어진 4개의 특성(Features)이 제공되며, 총 150개의 샘플 데이터가 있습니다. 각 품종당 50개의 샘플이 균등하게 분포되어 있어 다중 클래스 분류 문제를 연습하기에 적합합니다.
https://scikit-learn.org/stable/api/sklearn.datasets.html#module-sklearn.datasets
sklearn.datasets
Utilities to load popular datasets and artificial data generators. User guide. See the Dataset loading utilities section for further details. Loaders: Sample generators:
scikit-learn.org
데이터셋
데이터셋(Dataset)은 머신러닝과 데이터 과학에서 모델을 학습, 검증, 테스트하기 위해 사용되는 데이터의 집합입니다. 데이터셋은 일반적으로 입력 데이터(Features)와 정답 레이블(Labels)로 구성되며, 학습용 데이터셋(Training Dataset), 검증용 데이터셋(Validation Dataset), 테스트용 데이터셋(Test Dataset)으로 나누어 사용합니다. 또한 모델을 학습시키고, 하이퍼파라미터를 조정하며, 최종 성능을 평가하는 데 사용됩니다. 데이터셋의 품질과 크기는 모델의 성능에 큰 영향을 미치기 때문에, 적절한 전처리(Preprocessing)와 특성 엔지니어링(Feature Engineering)이 중요합니다.
데이터 준비
필요한 데이터셋을 준비합니다 이번에는 CSV 파일을 직접 준비하지 않고 사이킷런에서 제공하는 데이터 셋 아이리스를 사용합니다.
from sklearn.datasets import load_iris데이터 저장 및 확인
iris = load_iris()
iris
데이터를 로드해서 확인해줍니다 특성 개수는 일단 4개로 이루어져 있습니다.
아이리스 데이터셋의 설명을 출력하기 위해 다음 코드를 실행합니다.
print(iris['DESCR'])(2) 데이터셋 주요 내용
- 입력 변수 (Features)
- 꽃받침 길이 (sepal length)
- 꽃받침 너비 (sepal width)
- 꽃잎 길이 (petal length)
- 꽃잎 너비 (petal width)
- 출력 변수 (Target, Class)
- 3가지 붓꽃 품종을 나타내는 숫자로 표현됨:
- 0: Iris Setosa
- 1: Iris Versicolor
- 2: Iris Virginica
- 3가지 붓꽃 품종을 나타내는 숫자로 표현됨:
- 샘플 개수
- 총 150개의 샘플이 있으며, 각 품종별로 50개씩 포함되어 있음.
- 결측치 없음
- 데이터셋에는 누락된 값이 없음.
data = iris['data']
data
- iris['data']에는 꽃의 특성 데이터가 들어있습니다.
- 2차원 배열 형태로 되어 있으며, **각 행(row)이 하나의 샘플(붓꽃 데이터)**를 나타냅니다.
feature_names = iris['feature_names']
feature_names
- iris['feature_names']에는 **컬럼 이름(특성 이름)**이 저장되어 있습니다.
- 붓꽃 데이터의 네 가지 특성을 의미합니다.
Pandas 데이터프레임 변환
import pandas as pd
df_iris = pd.DataFrame(data, columns=feature_names)
df_iris
- NumPy 배열 형태의 데이터를 Pandas 데이터프레임으로 변환합니다.
- columns=feature_names를 설정하여 컬럼 이름을 추가합니다.
target = iris['target']
target
- iris['target']에는 **품종 정보(정답 레이블)**가 저장되어 있습니다.
- 각 숫자는 품종을 나타냄:
- 0: Setosa
- 1: Versicolor
- 2: Virginica

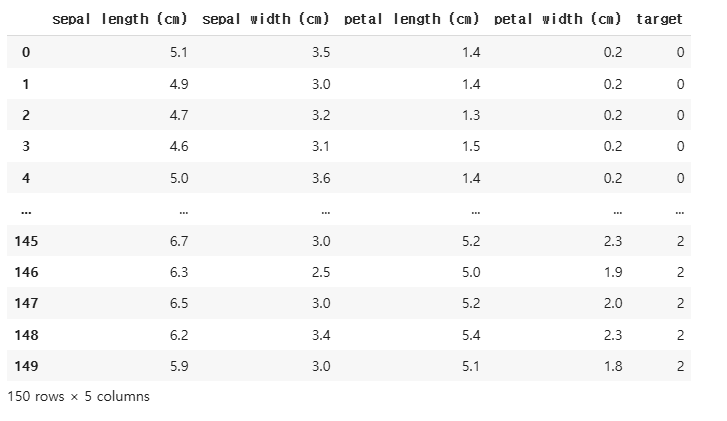
df_iris['target'] = target
df_irisdf_iris 데이터프레임에 target 컬럼을 추가하여 품종 정보를 포함합니다.
학습 데이터와 테스트 데이터 분할
from sklearn.model_selection import train_test_splittrain_test_split을 사용하여 데이터를 훈련 데이터(Train)와 테스트 데이터(Test)로 나눔.
X_train, X_test, y_train, y_test = train_test_split(df_iris.drop('target', axis=1),
df_iris['target'],
test_size=0.2,
random_state=2025)
- df_iris.drop('target', axis=1):
- target 컬럼을 **제거(drop)**하고, **입력 데이터(특성)**만 사용합니다.
- 즉, X 값으로 꽃받침/꽃잎 길이와 너비만 포함합니다.
- df_iris['target']:
- y 값으로 붓꽃 품종(0, 1, 2)를 사용합니다.
- test_size=0.2:
- 데이터의 20%를 테스트 데이터로 사용.
- 150개 샘플 중 120개는 훈련 데이터(X_train, y_train), **30개는 테스트 데이터(X_test, y_test)**로 분할.
- random_state=2025:
- 랜덤 시드 값(2025)을 고정하여 실행할 때마다 같은 데이터 분할 결과가 나오도록 함.
print(X_train.shape, X_test.shape)
print(y_train.shape, y_test.shape)
#(120, 4) (30, 4)
#(120,) (30,)
서포트 벡터 머신(Support Vector Machine, SVM)
서포트 벡터 머신(SVM)은 두 개 이상의 클래스(Class)를 구분하는 지도 학습(Supervised Learning) 알고리즘입니다. 주로 분류(Classification) 문제를 해결하는 데 사용되며, 일부 경우 회귀(Regression) 문제에도 사용됩니다. SVM의 목표는 두 클래스 간의 경계를 가장 잘 구분하는 최적의 초평면(Hyperplane)을 찾는 것입니다.
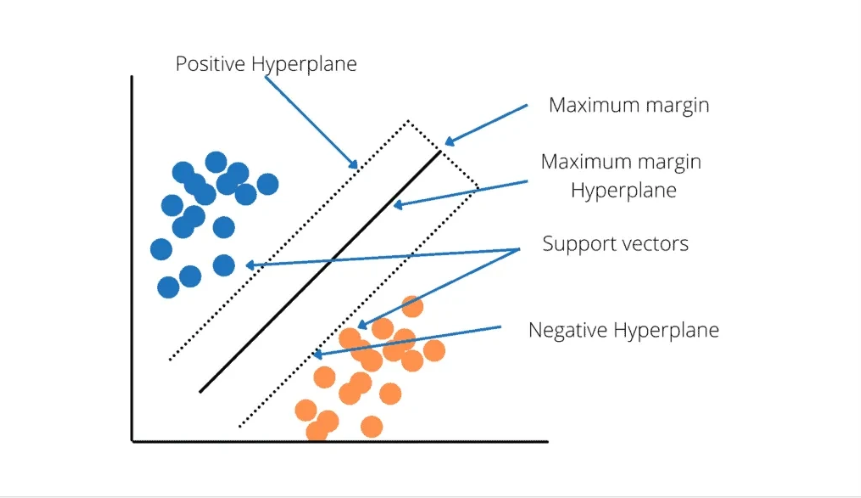
SVC
SVC(Support Vector Classifier)는 서포트 벡터 머신(SVM, Support Vector Machine)을 사용한 분류(Classification) 알고리즘입니다. 사이킷런(sklearn.svm.SVC)에서 제공되며, 이진 분류(Binary Classification)와 다중 클래스 분류(Multi-Class Classification) 문제를 해결할 수 있습니다.
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
- sklearn.svm 모듈에서 SVC(Support Vector Classification) 모델을 불러옵니다.
- SVM(Support Vector Machine)은 결정 경계(Decision Boundary)를 최대화하여 분류하는 지도 학습 알고리즘입니다.
- 비선형 데이터를 분류할 수도 있도록 커널(Kernel) 트릭을 지원합니다.
- sklearn.metrics의 accuracy_score() 함수는 정확도를 측정하는 함수입니다.
accuracy_score
accuracy_score는 사이킷런(sklearn)의 metrics 모듈에서 제공하는 성능 평가 지표로, 분류(Classification) 모델의 예측 정확도(Accuracy)를 측정하는 함수입니다. 이 함수는 모델이 예측한 값과 실제 정답이 얼마나 일치하는지를 백분율로 나타내며, 전체 샘플 중 올바르게 예측된 샘플의 비율을 계산합니다.
Accuracy
정확도(Accuracy)는 머신러닝과 통계학에서 모델의 성능을 평가하는 가장 기본적인 지표 중 하나로, 전체 예측 중에서 얼마나 많은 예측이 실제 정답과 일치했는지를 나타내는 비율입니다.

svc = SVC()
svc.fit(X_train,y_train)
- SVC()를 호출하여 Support Vector Classifier 객체를 생성합니다.
- 기본적으로 **RBF 커널(Radial Basis Function kernel)**을 사용하며, 다른 커널(linear, poly, sigmoid)도 설정할 수 있습니다.
- 주요 하이퍼파라미터:
- C: 규제(Regularization) 강도 (기본값: 1.0)
- kernel: 사용할 커널 함수 (기본값: 'rbf')
- gamma: RBF 커널에서 사용되는 값 (기본값: 'scale')
- degree: 다항식 커널(Poly Kernel)에서 차수(Degree) (기본값: 3)
- fit() 함수는 SVM 모델을 훈련 데이터(X_train, y_train)로 학습시킵니다.
- 입력 데이터(X_train): 붓꽃의 특성 값 (꽃받침 길이/너비, 꽃잎 길이/너비)
- 타겟 값(y_train): 붓꽃의 품종(0, 1, 2)
학습이 끝나면 최적의 결정 경계를 찾아 데이터셋을 분류하는 모델이 완성됩니다.
y_pred = svc.predict(X_test)
y_pred
- predict(X_test)를 사용해 훈련된 모델로 테스트 데이터(X_test)의 품종을 예측합니다.
- y_pred에는 예측된 품종 값이 저장됩니다.

print('정답률',accuracy_score(y_test,y_pred))
accuracy_score(y_test, y_pred)는 실제 정답(y_test)과 모델이 예측한 값(y_pred)을 비교하여 정확도를 계산합니다.
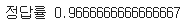
정답률은 0.96으로 모델은 96%가량의 정확도를 보이고 있다는 것을 알 수 있다
✅ SVC()를 사용하여 SVM 분류기를 쉽게 구현할 수 있음.
✅ fit()으로 학습하고, predict()로 예측한 후 accuracy_score()로 평가 가능.
✅ 아이리스 데이터셋에서는 기본 설정(rbf 커널)만으로도 96% 정확도 달성이 가능.
'AI ML LLM > 데이터분석' 카테고리의 다른 글
| 서울 자전거 공유 수요 예측 데이터셋 (4) | 2025.02.01 |
|---|---|
| 주택 임대료 예측 데이터셋 (0) | 2025.01.31 |
| 텐서(Tensor) (2) | 2025.01.29 |
| 파이토치 프레임워크 (0) | 2025.01.29 |
| 머신러닝 (2) | 2025.01.29 |



