논문 개요
- 제안된 구조: Seq2Seq (Sequence to Sequence)
- 핵심 아이디어: 두 개의 LSTM (Encoder & Decoder)을 사용하여 가변 길이 시퀀스를 다른 시퀀스로 변환
- 적용 문제: 영어 → 프랑스어 기계 번역 (WMT’14 데이터셋)
- 성과: 기존 phrase-based SMT보다 높은 BLEU 점수 획득
Sequence to Sequence란?
Seq2Seq는 하나의 시퀀스(입력)를 받아, 또 다른 시퀀스(출력)로 변환하는 모델 구조입니다.
Seq2Seq 구조
- Encoder LSTM: 입력 문장 x₁, x₂, ..., xₙ을 읽어들여 고정된 벡터 표현 v로 압축
- Decoder LSTM: v를 입력받아 출력 문장 y₁, y₂, ..., yₘ 생성
[입력 시퀀스] → [Encoder RNN] → Context Vector → [Decoder RNN] → [출력 시퀀스]Input (ex: 나는 열심히 일을 한다) → [Encoder LSTM] → context vector v
→ [Decoder LSTM] → Output (ex: I work hard)
Encoder:
- 입력 시퀀스를 순서대로 읽으며 LSTM을 통해 하나의 고정된 벡터(context vector)로 압축
- 예: "나는 열심히 일을 한다" → c
Decoder:
- context vector를 기반으로 출력 시퀀스를 하나씩 생성
- 예: c → "I work hard"
Seq2Seq 모델은 Encoder(인코더)와 Decoder(디코더) 두 부분으로 구성됩니다. 한국어 문장 "나는 열심히 일을 한다"를 영어 문장 "I work hard"로 번역하는 과정으로 설명 하자면 다음과 같습니다. ( 아래 그림 예시 참고)

인코더는 각 단어 "나는 열심히 일을 한다" 를 LSTM 에 순차적으로 입력하면서 문맥을 학습합니다. 마지막 LSTM 셀에서 전체 문장의 의미를 담은 "문맥 벡터(Context Vector)"를 생성합니다. 이 문맥 벡터가 디코더로 전달됩니다. 디코더는 컨텍스트 벡터(Context Vector)를 받아서, 새로운 언어(영어)로 문장을 생성하게 됩니다. 문장을 생성할 때 순차적으로 단어를 예측하면서 번역을 수행합니다. 디코더의 첫 입력은 <sos>(Start of Sentence) 토큰이며, 이후 번역을 수행합니다. 최종적으로 "나는 열심히 일을 한다" → "I work hard" 번역을 수행하게 됩니다. (<eso> 는 문장의 끝을 의미)
Seq2Seq 모델의 예로 BERT가 있으며 발전된 모델의 예로 BART가 있습니다. BART 의 인코더는 입력 문장을 손상(Corruption)시켜 일부 단어를 마스킹(masking)하거나, 단어 순서를 섞어서 학습합니다.
"나는 열심히 일을 한다" 라는 문장을 예로 들어 BART의 구조에 대해 더 자세히 설명하겠습니다. ( 아래 그림 예시 참고)
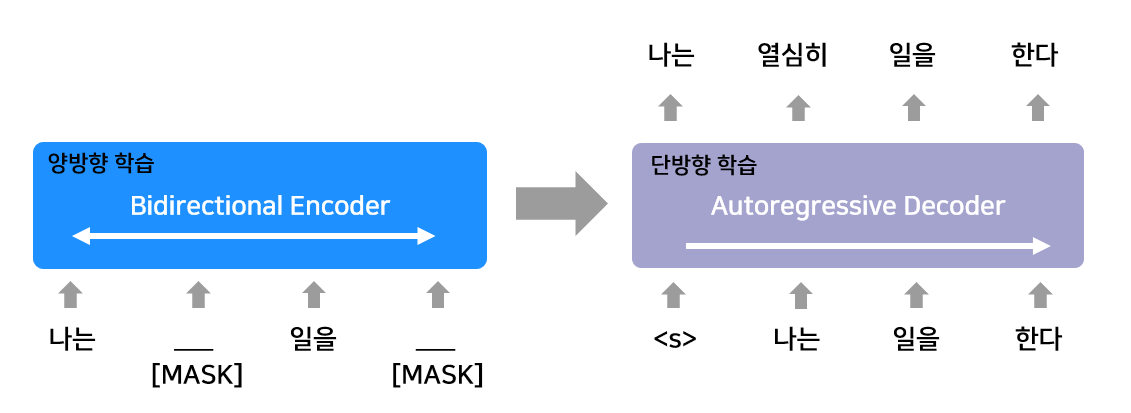
"열심히"와 "한다" 단어가 마스킹(masking) 되어 제거되고 양방향(Bidirectional)으로 문맥을 학습하여, 마스킹된 단어를 예측할 수 있도록 학습됩니다. 즉, 인코더는 마스킹된 문장을 보면서 문맥을 학습하는 역할을 합니다 모든 단어를 동시에 처리하여 전체 문맥을 학습하는 것이죠 BART 의 디코더는 Auto-Regressive(순차적) 방식으로 단어를 하나씩 예측하면서
원래 문장을 복원합니다. 디코더는 <s> (시작 토큰)에서 시작하며 이전에 생성된 단어를 바탕으로 다음 단어를 예측합니다
최종적으로 "나는 열심히 일을 한다" 문장을 완성하게 됩니다
Reversed Input Trick
- 입력 문장을 거꾸로 처리 (ex: 한다, 일을, 열심히, 나는)
- 이유: 인코더 벡터와 디코더 출력 간의 단기 의존성(short-term dependency)을 높여 학습 최적화가 쉬워짐
LSTM 선택 이유
- 긴 시퀀스에서도 장기 의존성(long-term dependency)을 학습 가능
- 단순 RNN은 긴 문장에서 정보 손실 문제 발생 → LSTM이 대안
논문 결론
“복잡한 기계 번역 시스템 없이도, 단순한 LSTM 기반 Seq2Seq 구조만으로 기존 SMT를 뛰어넘는 번역 성능을 달성할 수 있다. 이 방식은 향후 다양한 시퀀스-투-시퀀스 태스크에 강력한 솔루션이 될 수 있다.”


