배경 및 목적
기존 Vanilla RNN은 Time Interval이 큰 데이터에 대한 지식을 잘 저장하지 못하는 한계점이 존재한다. 이러한 한계점은 Error back flow(back propagation)과정이 정보를 충분히 전달하지 못하기 때문이고, 수 많은 Layer를 지나면서 Weight가 Vanishing 되기 때문이다.
본 논문에서는 이러한 문제점을 해결할 수 있는 novel, efficient gradient-based method인 LSTM(Long Short-Term Memory)를 제안한다. LSTM에서는 특정 정보가 Gradient에 안좋은 영향을 미치지 않는 한, 약 1000번의 time step 이상의 interval에도 정보를 소실하지 않고 효과적으로 정보를 전달할 수 있다. 본 논문에서는 인위적으로 만들어낸 다양한 패턴들에 대해서 LSTM을 적용시켜 RTRL, BPTT, Recurrent Cascade-Correlation, Elman nets, Neural Sequence Chnking등과 비교해보았으며, 실험을 통해 LSTM의 우수함을 입증하였다. 단순히 성능 지표만 높을 뿐 아니라, 기존 RNN류 모델들이 풀지 못했던 Long Time Lag Task에서 최초로 성공을 거두었다고한다.
Long Short-Term Memory(LSTM)
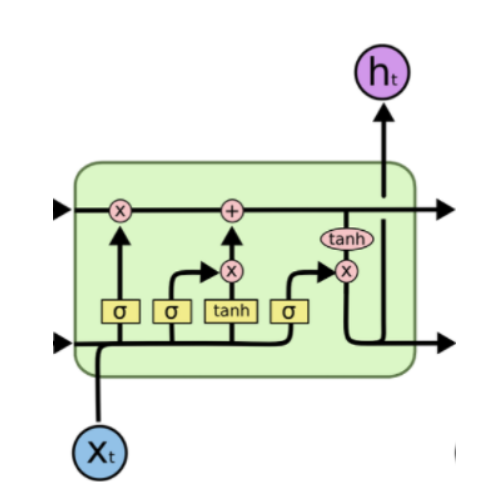
LSTM Cell의 구조는 위와 같다.
기존 Vanilla RNN이 hidden state만을 사용하던 것과 달리, LSTM에서는 Cell State라는 새로운 Flow를 도입하였다. 이는 마치 컨베이어 벨트처럼 이전에 입력됐던 정보들을 전달해주는 역할을 한다. 이전 Cell에서 넘어온 hidden state에 대해서 과거의 정보중 어느 것을 Cell State에 반영할 것인지를 정하는 Forget Gate(불필요한 정보를 잊는다는 의미), 현재 입력된 정보를 얼마나 Cell State에 반영할 것인지를 정하는 Input Gate, 다음 Cell에 전달할 hidden state 값에 Cell State를 얼마나 반영할 것인지를 정하는 Output Gate로 구성된다.
Forget Gate
과거에서 넘어온 정보 중, 불필요하다고 여겨지는 데이터들을 삭제해주는 역할을 한다. 정확히는 삭제라기보다는, Sigmoid 함수를 통해 얻어진 0~1 사이의 가중치를 곱해줘서 학습을 하면서 상대적으로 중요한 정보에는 높은 가중치를, Gradient 갱신에 별로 좋지 않은 영향을 끼치는 정보에 대해서는 낮은 가중치를 가지게 한다. 즉 Neural Network를 학습하여 얻어진 W_f(Weight of Forget Gate)와 B_f(Bias of Forget Gate)를 바탕으로 0에 가까운 값이 나오면 정보를 버리는 효과, 아예 0이 되면 삭제 반대로 1에 가까울 수록 정보 보존, 1일 경우 데이터 그대로 전달의 역할을 함으로써 Cell을 지나면서도 계속적으로 유의미한 데이터들은 Cell State Flow에 보존되도록 한다.
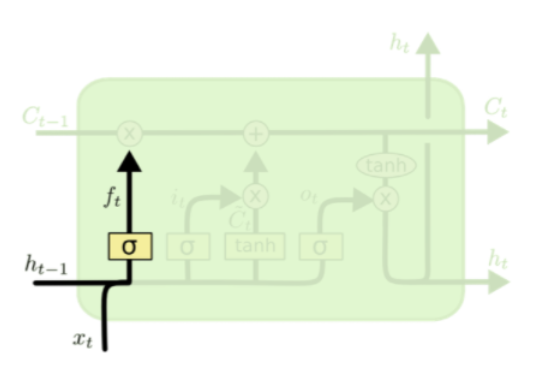
Input Gate
현재의 입력값 X_t와 이전 hidden state를 적절히 사용하여 현재 Cell의 Local State를 얻어내고, 이를 Global Cell State에 얼마나 반영할지를 결정하는 게이트이다.
마찬가지로 Sigmoid 함수를 사용하므로, 현재 시점에서 얻은 정보가 큰 효용가치가 있을 경우 Cell State에 많이 반영하고, 별로 의미가 없는 데이터일 경우에는 0에 가까운 가중치를 줘서 반영을 최소화한다.

이후, 과거 hidden state에서 적절히 forget이 이루어진 cell state와, 현재 cell에서 얻을 수 있는 새로운 데이터를 반영한 cell state를 더해서 최종적인 global cell state를 update하게 된다.

Output Gate

최종적으로 얻어진 Cell State 값에서 어느정도를 취해서 Hidden State로 전달할 것인지를 정하는 마지막 Gate이다.
여기서 최종적으로 얻어진 h_t를 바탕으로 다음 셀에서는 C_t+1을 구하게 된다.
LSTM 예시 설명
위의 Forget gate Input gate Output gate를 각각 예시를 들어서 더 쉽게 설명해 보겠다.
태스크는 리뷰 감정 분석으로 예를 들겠다.
“처음에는 별로였지만, 시간이 지날수록 정말 좋아졌어요.”
Vanilla RNN
위와같은 문장이 있다고 하면 Vanilla RNN의 경우 문장 초반에 나온 "별로였다"라는 부정적 표현이 RNN에 영향을 끼쳐 전체 문장이 부정적이라고 잘못 판단할 수 있다. 왜냐하면 RNN은 후반부 "정말 좋아졌어요"에 도달했을 때는 기울기 소실로 인해 앞의 정보가 사라졌거나 약화됐기 때문이다.
LSTM
하지만 LSTM의 경우 Forget Gate를 통해서 "처음에는 별로였다"는 부정적인 감정을 나중에 "좋아졌다"는 긍정 표현에 따라 덜 중요하게 반영하게 된다.
Cell State: 시퀀스 전반에 걸쳐 정보를 효율적으로 유지하게 된다.
결과적으로 후반부 정보를 충분히 반영하여 긍정으로 분류할 수 있다.

두번째 예시로 는 번역을 예로 들어 보겠다
"나는 오늘 아침에 기차를 타고 서울에 갔어요." (한국어 → 영어 번역)
목표:
“I went to Seoul by train this morning.”
이 문장에서 핵심은 한국말로 "서울에 갔어요 " 라고 볼 수 있다.
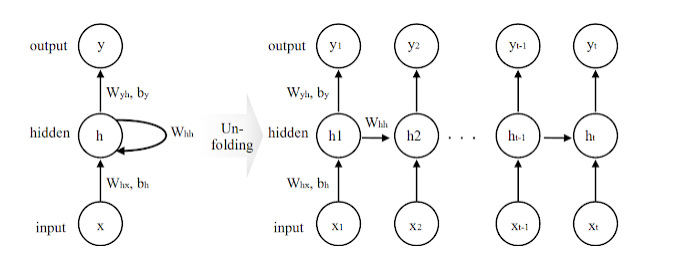
Vanilla RNN
각 단어를 시간순으로 처리하면서 hidden state에 정보를 축적한다

RNN의 흐름
- 각 단어 xₜ가 입력됨 → 임베딩 후 hidden state hₜ 계산
- hₜ는 이전 hidden state hₜ₋₁와 함께 계산됨 → 문맥 포함
- 최종 hidden state h₇은 Decoder로 넘어가 번역 시작
- Decoder는 각 yₜ를 순차적으로 생성 (오토리그레시브하게)
하지만 마지막 단어 "갔어요"가 번역의 핵심(→ went)이지만, 앞선 단어들이 너무 많아져서 h₇에선 정보가 희석 될 가능성이 높다. 따라서 y₇ (출력 "went")이 잘못 생성될 수도 있음
LSTM
나는 / 오늘 / 아침에 / 기차를 / 타고 / 서울에 / 갔어요
→ 입력 시퀀스: x₁ ~ x₇
→ 시간축에 따라 각 시점 t에서 하나의 단어가 들어감


Forget Gate
- 이 단계에서는 이전까지 기억(Ct-1) 중에서 무엇을 지울지 결정합니다.
- 예: 지금 시점 t=4, 입력 단어 기차를
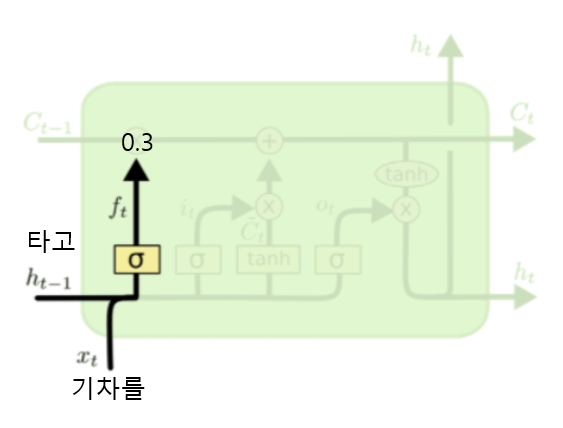
- “기차를”이 들어오면 LSTM은 “나는”, “오늘” 등 초기 단어 중 일부를 덜 중요하다고 판단
- → ft 값이 작아짐 → 과거 기억을 일부 지움
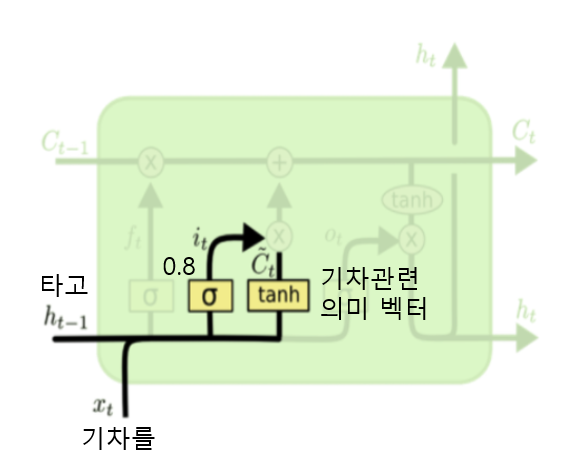
Input Gate (it), Candidate Cell State (C~t)
- 현재 단어 xt를 바탕으로 새로운 정보를 얼마나 저장할지 결정
- Candidate 정보: 현재 들어온 기차를을 얼마나 중요한 정보로 간주할지
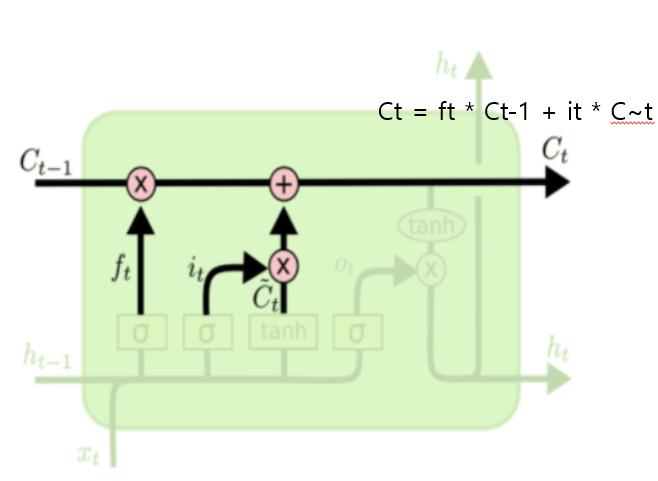
Cell State 업데이트 (Ct)
- 과거 기억 중 일부는 Forget Gate에 의해 지워지고,
현재 정보는 Input Gate에 따라 추가됨 - 이로써 최신 Ct가 구성됨
이전 문맥 중 “나는 오늘 아침에”는 흐려지고, “기차를 타고”가 강조됨
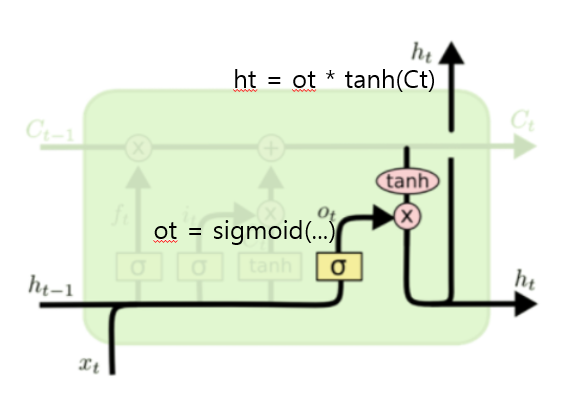
[4] Output Gate (ot) → hidden state ht 계산
- 최종 Cell State Ct에서 얼마나 정보를 노출할 것인지 결정
- tanh(Ct)와 ot 값을 곱하여 hidden state(ht) 생성
이 시점의 ht는 번역 결과 “by train”으로 연결됨
전체 구조 요약
- xt = 기차를, ft: “과거 정보 잊을지 결정”
- it: “현재 입력 저장할지 결정”
- C~t: “입력 후보 정보 생성”
- Ct: “최종 셀 상태”
- ot: “얼마나 드러낼지”
- ht: “출력될 정보 = 번역: 'by train'"

위와 같이 LSTM은 Cell State를 통해 장기 정보를 유지하면서, Forget/Input/Output 게이트를 통해 정보의 흐름을 제어한다. 따라서 "나는 오늘 아침에 기차를 타고 서울에 갔어요"와 같이 긴 문장에서 마지막 단어인 '갔어요'의 핵심 의미도 h₇과 C₇에 충분히 보존되어, y₇(→ went)이 정확히 생성될 가능성이 높다.


