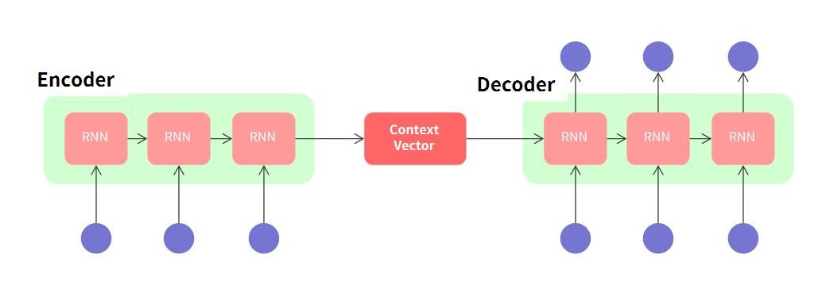
배경 및 목적 : RNN Encoder–Decoder + GRU
- 존 통계적 기계 번역(SMT)은 단순한 통계 기반, 고정된 표현, 순서 정보 미포함 등 한계가 있었음
- 이를 개선하기 위해 가변 길이 시퀀스를 다룰 수 있는 RNN 기반 Encoder–Decoder 구조를 제안
- 더 나아가 학습이 쉽고 계산이 간단한 GRU(Gated Recurrent Unit)을 함께 도입함
핵심 제안
RNN Encoder–Decoder 구조
- Encoder RNN: 입력 문장(x₁, ..., xₜ)을 **고정 길이 벡터(c)**로 인코딩
- Decoder RNN: 이 벡터(c)를 기반으로 출력 문장(y₁, ..., yₜ') 생성
즉, 시퀀스 → 벡터 → 시퀀스로의 변환 구조
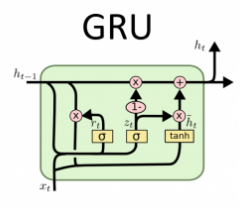
GRU 셀 도입 (LSTM 간소화 버전)
- 기존 LSTM보다 더 간단하고 빠르게 학습 가능
- 내부에 두 개의 게이트만 존재:
- Update Gate (zₜ): 기억할지, 덮어쓸지 결정
- Reset Gate (rₜ): 이전 정보를 얼마나 무시할지 결정
분석
- GRU 기반 모델은 긴 문장, 드문 표현에 대해 더 자연스러운 번역 생성 가능
- 예시:
- 입력: at the end of the
- 기존 모델 출력: 단순히 빈도 높은 표현
- GRU 출력: 문맥에 맞는 다양한 표현 (à la fin de la, à la fin du, 등)
결론
- GRU 기반 RNN Encoder–Decoder는
- 기계 번역에 효과적이고,
- 고정된 표현에 의존하지 않고 문장 구조/의미를 반영한 표현을 학습함
- 기존 phrase-based SMT에 보조적인 neural feature로 넣거나, 향후에는 기존 phrase table 자체를 대체 가능할 잠재력 보임
LSTM VS GRU
LSTM
LSTM(Long Short-Term Memory)은 RNN의 장기 의존성 문제를 해결하기 위해 고안된 모델입니다. LSTM은 셀 상태(cell state)와 3개의 게이트(입력 게이트, 출력 게이트, 망각 게이트)를 사용하여 중요한 정보를 오랫동안 저장하고 불필요한 정보를 제거하는 구조를 갖추고 있습니다. 망각 게이트는 이전 셀 상태에서 필요 없는 정보를 삭제하고, 입력 게이트는 새로운 정보를 저장하며, 출력 게이트는 최종 출력을 결정합니다. 이러한 구조 덕분에 LSTM은 장기 시퀀스를 다루는 자연어 처리, 음성 인식, 시계열 예측 등의 다양한 분야에서 효과적으로 사용됩니다. 하지만 구조가 복잡하여 계산량이 많고, 학습 시간이 오래 걸린다는 단점이 있습니다.
GRU
GRU(Gated Recurrent Unit)는 2014년 뉴욕대학교(NYU) 조경현(Kyunghyun Cho) 교수 연구팀이 제안한 RNN의 장기 의존성 문제를 해결하기 위해 개발한 신경망 구조입니다. LSTM과 유사한 성능을 가지면서도 더 간단한 구조를 갖고 있어 연산량이 적고 학습 속도가 빠릅니다. GRU는 업데이트 게이트(Update Gate)와 리셋 게이트(Reset Gate)라는 두 개의 게이트만을 사용하여 정보를 조절하며, LSTM보다 파라미터 수가 적어 적은 데이터셋에서도 효과적으로 학습할 수 있습니다. 업데이트 게이트는 이전 정보를 얼마나 유지할지 결정하고, 리셋 게이트는 새로운 정보를 반영하기 위해 기존 정보를 얼마나 잊을지 조정합니다. 이러한 특성 덕분에 GRU는 텍스트 처리, 음성 인식, 시계열 예측 등에서 LSTM보다 더 빠르고 효율적으로 사용할 수 있지만, 장기 의존성이 중요한 경우 LSTM이 더 나은 성능을 보일 수도 있습니다.
GRU (Gated Recurrent Unit)
| 항목 | LSTM (Long Short-Term Memory) | |
| 구조 복잡도 | 더 복잡함 (3개의 게이트 + Cell State) | 간단함 (2개의 게이트, Cell State 없음) |
| 기억 관리 | Cell State(Cₜ)로 장기 기억 유지 | Hidden State(hₜ)만으로 기억 유지 |
| 학습 속도 | 느림 (파라미터 많음) | 빠름 (연산량 적음) |
| 성능 | 장기 의존성에 강함 (긴 문장, 시계열) | LSTM과 유사한 성능 (짧은 문장에 강함) |
| 구성 요소 | Forget Gate, Input Gate, Output Gate, Cell State | Update Gate, Reset Gate |
| 해석 가능성 | 게이트 별로 역할이 분리되어 있어 해석 쉬움 | 상대적으로 해석은 복합적 |
| 실험적 특징 | 긴 시퀀스에서 우수한 성능 | 소형 모델, 빠른 추론 시 강점 |
| 적용 예 | 번역, 챗봇, 긴 뉴스 요약 | 모바일 디바이스, 실시간 예측 |
'인공지능 > 논문' 카테고리의 다른 글
| Attention Is All You Need(Transformer) (0) | 2025.03.18 |
|---|---|
| “Sequence to Sequence Learning with Neural Networks” (Ilya Sutskever et al., 2014) (0) | 2025.03.18 |
| LSTM: long short-term memory (0) | 2025.03.18 |


