1.데이터프레임 합치기
아래 파일을 다운받고 추가로 구글드라이브에 업로드합니다.
idol (1).csv
0.00MB
idol2 (1).csv
0.00MB
df1 = pd.read_csv('내 드라이브 경로/idol (1).csv')
df2 = pd.read_csv('내 드라이브 경로/idol2 (2).csv')df1
df2
df_copy = df1.copy()pd.concat([df1, df_copy]) # axis=0 (기본값)
df_concat = pd.concat([df1, df_copy])
# reset_index(): index를 새롭게 적용
# drop=True 옵션을 사용하여 기존 index가 컬럼으로 만들어지는 것을 방지
df_concat.reset_index(drop=True)
#concat 행으로 붙이기
pd.concat([df1, df2], axis=1) # 같은 index끼리 결합
df3 = df2.drop([1,3,5,7,9])
df3pd.concat([df1, df3], axis=1) # 맞는 인덱스가 없는 부분은 NaN으로 뜸
df_right = df2.drop([1, 3, 5, 7, 9], axis=0)
df_right
df_right = df_right.reset_index(drop=True)
df_right
dic = {
'이름': '김사과',
'연봉': 9000,
'가족수': 10
}df_right = pd.concat([df_right, pd.DataFrame(dic, index=[0])], ignore_index=True)
df_right
pd.concat([df1, df_right], axis=1) # 해당 인덱스가 서로 맞아야 정상적으로 합쳐지니 주의하자
# merge(): 특정 고유한 키(unique, id)값을 기준으로 합침
# merge(데이터프레임1, 데이터프레임2, on='유니크값', how='병합의 기준')
# 병합의 기준: left, right, inner, cross
pd.merge(df1, df_right, on='이름', how='left') #왼쪽은 데이터 다 나오고 오른쪽을 왼쪽에 합침
pd.merge(df1, df_right, on='이름', how='right')#오른쪽은 데이터 다 나오고 왼쪽을 오른쪽에 합침
pd.merge(df1, df_right, on='이름', how='inner') #교집합
pd.merge(df1, df_right, left_on='이름', right_on='성함', how='inner')
2. 등수 매기기
# rank(): 데이터프레임 또는 시리즈의 순위를 매기는 함수. 기본값은 ascending(오름차순)
df1['브랜드순위'] = df1['브랜드평판지수'].rank()
df1
df1['브랜드순위'] = df1['브랜드평판지수'].rank(ascending=False)
df1
# astype(): 특정열의 자료형을 변경
df1['브랜드순위'] = df1['브랜드순위'].astype(int)
df1
df1['브랜드순위'].dtypes
# dtype('int64')
# rank(): 데이터프레임 또는 시리즈의 순위를 매기는 함수. 기본값은 ascending(오름차순)
df1['브랜드순위']
3. 날짜타입 사용하기
df['birthday']
# to_datetime(): object타입에서 datetime타입으로 변환
df['birthday'] = pd.to_datetime(df['birthday'])
print(type(df['birthday']))
print(df['birthday'].dtypes)
#<class 'pandas.core.series.Series'>
datetime64[ns]df.info()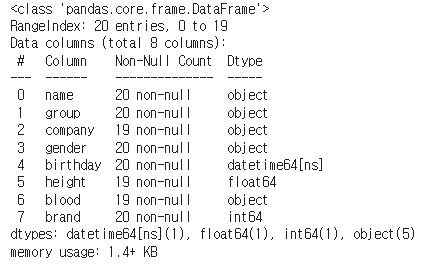
df['birthday'].dt.year #년도만 뽑아오기
df['birthday'].dt.month
df['birthday'].dt.day
df['birthday'].dt.hour
df['birthday'].dt.minute
df['birthday'].dt.second
df['birthday'].dt.dayofweek # 요일: 0(월요일) ~ 6(일요일)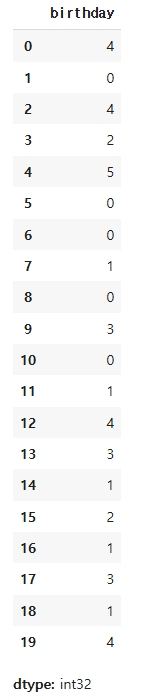
df['birthday'].dt.isocalendar().week
4. apply 사용하기
- Pandas의 apply() 함수는 데이터프레임이나 시리즈의 데이터를 사용자 정의 함수 또는 내장 함수에 적용하여 새로운 값을 계산하거나 변환할 때 사용됩니다. 데이터를 행(row) 또는 열(column) 단위로 처리할 수 있는 강력한 도구입니다.
중요!
df.head()
df_copy = df.copy()
df_copy#문자는 못알아 들으니까 라벨인코딩으로 숫자로 변환을 꼭 해줘야함 이때 사용하는게 apply
# 성별을 남자는 1, 여자는 0으로 변환(loc를 사용)
df_copy.loc[df_copy['gender'] == '남자', 'gender'] = 1
df_copy.loc[df_copy['gender'] == '여자', 'gender'] = 0df_copy.head()
df_copy = df.copy()
df_copydef male_or_female(x):
if x == '남자': #남자 들어오면 1 리턴
return 1
elif x == '여자': #여자 들어오면 0 리턴
return 0
else:
return Noneprint(male_or_female('남자'))
print(male_or_female('여자'))df_copy['gender'].apply(male_or_female)
df_copy['gender'].apply(lambda x: 1 if x == '남자' else 0)
df_copy['NewGender']= df_copy['gender'].apply(lambda x: 1 if x == '남자' else 0)
df_copy.head()
5. map 사용하기
Pandas의 map() 함수는 Series 객체에서 사용할 수 있는 함수로, 각 요소에 대해 함수나 매핑 규칙을 적용하여 새로운 값을 계산하거나 변환할 때 사용됩니다. map()은 데이터의 각 요소를 순회하며 특정 작업을 수행하므로, 데이터를 가공하거나 변환하는 데 유용합니다.
df_copy = df.copy()
df_copy.head()
map_gender = {'남자':1, '여자':0}df_copy['gender'].map(map_gender)
df_copy['New_Gender'] = df_copy['gender'].map(map_gender)
df_copy.head()
위와 같이 맵 함수를 사용하면 요소에 매핑 규칙을 정의해서 더 쉽게 데이터를 변환할 수 있다
6. 데이터프레임의 산술연산
df1 = pd.DataFrame({
'파이썬':[60, 70, 80, 90, 95],
'데이터분석':[40, 60, 70, 55, 87],
'머신러닝딥러닝':[35, 40, 30, 70, 55]
})
df1
df1['파이썬'].dtypes
# dtype('int64')
type(df1['파이썬'])
df1['파이썬'] + df1['데이터분석'] + df1['머신러닝딥러닝']
이와 같이 데이터 프레임에서 연산도 가능하다
# df에 총점, 평균이라는 파생변수를 만들고 파생변수에 총점, 평균을 구해서 저장
df1['총점'] = df1['파이썬'] + df1['데이터분석'] + df1['머신러닝딥러닝']
df1['평균'] = df1['총점'] / 3
df1
df1['파이썬'].sum() # df1['파이썬'].sum(axis=0)
# 395df1['파이썬'].mean()
# 79.0df1.sum()
df1.mean()
df1 = pd.DataFrame({
'파이썬':[60, 70, 80, 90, 95],
'데이터분석':[40, 60, 70, 55, 87],
'머신러닝딥러닝':[35, 40, 30, 70, 55]
})
df2 = pd.DataFrame({
'파이썬':['C', 'B', 'B', 'A', 'A'],
'데이터분석':[40, 60, 70, 55, 87],
'머신러닝딥러닝':[35, 40, 30, 70, 55]
})
# df1 + df2 # TypeError: unsupported operand type(s) for +: 'int' and 'str'
df1 + 10
# df2 + 10 # TypeError: can only concatenate str (not "int") to str
df1 = pd.DataFrame({
'데이터분석':[40, 60, 70, 55, 87],
'머신러닝딥러닝':[35, 40, 30, 70, 55]
})
df2 = pd.DataFrame({
'데이터분석':[40, 60, 70, 55],
'머신러닝딥러닝':[35, 40, 30, 70]
})
df1 + df2 # 행의 갯수가 다를 경우 빠진 데이터를 NaN으로 취급하기 때문에 결과는 NaN
7. select_dtypes
df = df.copy()
df.head()df.select_dtypes(include='object') # 문자열 컬럼만 가져오기
df.select_dtypes(exclude='object') # 문자열 컬럼만 빼고 가져오기
# 문자가 아닌 컬럼에만 10을 더함
df.select_dtypes(exclude=['object','datetime64[ns]']) + 10
str_cols = df.select_dtypes(include='object').columns
str_cols
# Index(['name', 'group', 'company', 'gender', 'blood'], dtype='object')df[str_cols]#object인 콜롬만 알아내서 저장
8. get_dummies
- get_dummies()는 Pandas에서 범주형 데이터를 원-핫 인코딩(one-hot encoding) 방식으로 변환하는 데 사용됩니다.
원-핫 인코딩은 각 범주를 별도의 열로 변환하고, 해당 범주에 해당하는 곳에 1(T)을, 나머지에는 0(F)을 채우는 방식입니다. 예를 들어, 데이터가 "Red", "Green", "Blue"와 같은 문자열이라면, 모델은 이를 이해하지 못합니다. 범주형 데이터를 숫자로 변환해야 모델이 계산할 수 있습니다(라벨인코딩). 원-핫 인코딩은 범주형 데이터를 숫자로 변환하면서도 각 범주 간의 순서나 크기를 부여하지 않습니다.
- 범주형 데이터 : 카테고리컬한것들 ex: 키 = 수치 데이터, 지역번호 : 서울 02 경기 03 같은게 범주형 데이터
- 해당 범주에 해당하는 곳에 1 (True)
- "Red"=1, "Green"=2, "Blue"=3 처럼 라벨 인코딩을 하면 연산을 해야하는건지 카테고리컬인지 모델은 구분하지 못하기 때문에 숫자의 연관성을 끊어서 다음과같이 만들어줘야 함
위 표와 같이 원핫 인코딩이 되는것이다
R G B 0 F F T 1 T F F 2 F T F
인덱스 0은 Blue 1은 Red 2는 Green을 나타내고 있음을 알 수 있다
blood_map = {'A':0, 'B':1, 'AB':2, 'O':3}
df['blood_code'] = df['blood'].map(blood_map) # 라벨 인코딩
df.head()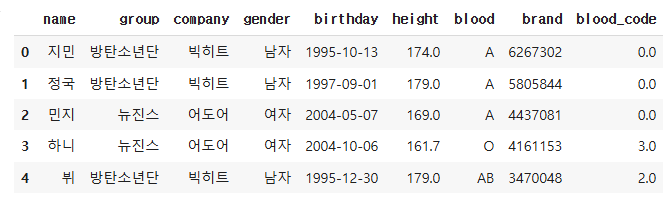
pd.get_dummies(df['blood'])
df = pd.get_dummies(df,columns=['blood'])
df.head()
df.info()
'인공지능 > 데이터분석' 카테고리의 다른 글
| online Retail 데이터셋 - 캐글 (0) | 2025.01.17 |
|---|---|
| Matplotlib (1) | 2025.01.17 |
| 판다스-기초1 (0) | 2025.01.16 |
| 넘파이 - 기초 (0) | 2025.01.16 |
| 텐서(Tensor) (0) | 2025.01.07 |



