1. 논리 회귀
논리 회귀(Logistic Regression)는 주어진 입력 데이터를 기반으로 두 가지 이상의 범주로 분류하는 지도 학습 알고리즘입니다. 주로 이진 분류 문제에 사용되며, 입력 변수의 선형 결합을 통해 특정 사건이 발생할 확률을 예측합니다. 이 알고리즘은 시그모이드(Sigmoid) 함수 또는 로지스틱 함수라는 비선형 함수를 사용하여 예측값을 0과 1 사이의 확률로 변환합니다. 모델의 결과는 일반적으로 특정 임계값(예: 0.5)을 기준으로 두 범주 중 하나로 분류됩니다. 예를 들어, 이메일이 스팸인지 아닌지를 판별하거나 환자의 병 진단 여부를 예측하는 데 사용될 수 있습니다. 논리 회귀는 계산이 비교적 간단하고 해석이 용이하여 머신러닝에서 널리 사용되는 알고리즘입니다.
※ 시그모이드 함수
시그모이드 함수(Sigmoid Function)는 입력 값을 받아서 이를 0과 1 사이의 값으로 변환하는 수학 함수입니다. 주로 확률을 예측해야 하는 문제에서 사용됩니다. 논리 회귀(Logistic Regression)와 인공신경망(Artificial Neural Network)에서 매우 중요한 역할을 합니다. (e: 자연 상수로, 약 2.718입니다.)

2. 단항 논리 회귀
단항 논리 회귀 (Univariate Logistic Regression)는 하나의 독립 변수(입력 변수)를 사용하여 이진 분류 문제를 해결하는 논리 회귀(Logistic Regression)의 한 형태입니다. 예를 들어, 학생의 하루 공부 시간(독립 변수)에 따라 시험 합격 여부(종속 변수: 합격/불합격)를 예측하는 경우가 여기에 해당합니다. 단항 논리 회귀는 입력 변수의 값을 시그모이드(Sigmoid) 함수에 전달하여 해당 사건(예: 합격)이 발생할 확률(0과 1 사이의 값)을 계산합니다. 이후 이 확률 값이 특정 임계값(일반적으로 0.5)을 초과하면 한 클래스로, 그렇지 않으면 다른 클래스로 분류합니다. 단항 논리 회귀는 간단하면서도 직관적이어서 이진 분류 문제를 설명하고 해석하는 데 자주 사용됩니다.
import torch
import torch.nn as nnx = torch.tensor([1.0, 2.0, 3.0])
w = torch.tensor([0.1, 0.2, 0.3])
b = torch.tensor(0.5)
# z = W1*x1 + W2*x2 + W3*x3 + b
# z = 0.1*1.0 + 0.2*2.0 + 0.3*3.0 + 0.5
0.1*1.0 + 0.2*2.0 + 0.3*3.0 + 0.51.9
z = torch.dot(w, x) + b
print(z)
#dot product 행렬곱tensor(1.9000)
sigmoid = nn.Sigmoid()
output = sigmoid(z)
print(output)tensor(0.8699)
import torch.optim as optim
import matplotlib.pyplot as plttorch.manual_seed(2025)x_train = torch.FloatTensor([[0], [1], [3], [5], [8], [11], [15], [20]])
y_train = torch.FloatTensor([[0], [0], [0], [0], [1], [1], [1], [1]])
print(x_train.shape)
print(y_train.shape)plt.figure(figsize=(8, 5))
plt.scatter(x_train, y_train)
model = nn.Sequential(
nn.Linear(1,1),
nn.Sigmoid()
)modellist(model.parameters())y_pred = model(x_train)
y_pred
BCE 손실 함수
Binary Cross Entropy (BCE)는 이진 분류 문제에서 모델이 예측한 확률 분포와 실제 정답 레이블 사이의 차이를 측정하는 손실 함수(Loss Function)입니다. BCE는 예측된 확률 값과 실제 값(0 또는 1) 사이의 차이를 로그 확률로 변환하여 손실을 계산합니다.
Binary Cross Entropy 이진 분류에만 쓰는거

# 손실값이 커지고 작아진다는건 참과 거짓에 더 가까워 진다는 뜻임 학습이 잘 되고있다는 뜻
# 0인데 1이면 틀렸으니까 조절 0인데 0이면 맞았으니까 그냥 두면됨loss = nn.BCELoss()(y_pred, y_train)
lossoptimizer = optim.SGD(model.parameters(), lr=0.01)epochs = 1000
for epoch in range(epochs):
y_pred = model(x_train)
loss = nn.BCELoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'Epoch: {epoch}/{epochs}, Loss: {loss: .6f}')
list(model.parameters())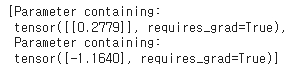
X_test = torch.FloatTensor([[10]])
y_pred = model(X_test)
y_predtensor([[0.8341]], grad_fn=<SigmoidBackward0>)# 임계치 설정하기
# 0.5보다 크거나 같으면 1
# 0.5보다 작으면 0
y_bool = (y_pred >= 0.5).float()
y_booltensor([[1.]])3. 다항 논리 회귀
다항 논리 회귀(Multinomial Logistic Regression)는 종속 변수가 세 개 이상의 범주로 나뉘는 다중 클래스 분류 문제를 해결하는 알고리즘입니다. 예를 들어, 과일의 색깔이 빨강, 노랑, 초록 중 하나로 분류되는 문제에서 사용할 수 있습니다. 이 알고리즘은 각 클래스에 대한 확률을 예측하기 위해 소프트맥스(Softmax) 함수를 사용합니다. 소프트맥스 함수는 각 클래스에 속할 확률을 0과 1 사이의 값으로 변환하며, 모든 클래스의 확률 합이 1이 되도록 정규화합니다. 모델은 입력 데이터가 특정 클래스에 속할 가능성을 계산한 뒤, 가장 높은 확률을 가진 클래스를 최종 예측 값으로 선택합니다. 다항 논리 회귀는 자연어 처리, 이미지 분류, 그리고 다양한 다중 클래스 분류 문제에서 널리 사용됩니다.
X_train = [[1, 2, 1, 1],
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 2, 5, 5],
[1, 6, 5, 5],
[1, 4, 5, 8],
[1, 7, 7, 7],
[2, 8, 7, 8],
[2, 7, 6, 7],
[2, 6, 6, 6]]
y_train = [0, 0, 0, 1, 1, 1, 2, 2, 2, 2]#관례적으로 xy값이 있는 매트릭스 형태면 대문자 씀
# 1차원인 벡터같은 것들은 소문자
x_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
print(x_train.shape)
print(y_train.shape)torch.Size([10, 4])
torch.Size([10])
#수식 만들기 가설세우기
model = nn.Sequential(
nn.Linear(4,3)
)
model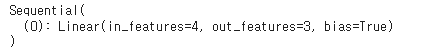

list(model.parameters())
#선형으로 각 값을 예측하는 선을 그려주는게 아래 녀석들
# [Parameter containing:
# tensor([[-0.2100, -0.1009, 0.2470, -0.4785],
# [-0.4346, 0.2855, -0.1117, 0.1340],
# [ 0.4447, -0.0227, -0.2139, -0.1113]], requires_grad=True),
y_pred = model(x_train)
y_pred
CrossEntropyLoss
CrossEntropyLoss는 다중 클래스 분류(Multiclass Classification) 문제에서 모델의 예측과 실제 정답 레이블 간의 차이를 측정하는 손실 함수(Loss Function)입니다. 이 함수는 모델이 예측한 확률 분포와 실제 레이블(정답) 간의 불확실성을 수치화합니다. CrossEntropyLoss는 주로 Softmax 함수와 함께 사용됩니다. Softmax는 각 클래스에 대한 확률 분포를 제공하며, CrossEntropyLoss는 이 확률 분포와 실제 레이블 간의 차이를 계산합니다. 예측이 실제 레이블과 가까울수록 손실 값이 작아지며, 예측이 틀릴수록 손실 값은 커집니다.


Softmax
Softmax 함수는 다중 클래스 분류(Multiclass Classification) 문제에서 사용되는 활성화 함수(Activation Function)입니다. 이 함수는 주어진 입력 벡터의 각 요소를 확률 분포(probability distribution)로 변환합니다. 즉, 각 클래스에 대한 예측값을 0과 1 사이의 값으로 변환하며, 모든 클래스의 확률 합이 항상 1이 되도록 정규화합니다.


loss = nn.CrossEntropyLoss()(y_pred, y_train)
losstensor(1.9676, grad_fn=<NllLossBackward0>)optimizer = optim.SGD(model.parameters(), lr=0.01)epochs = 10000
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.CrossEntropyLoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f'Epoch: {epoch}/{epochs} Loss: {loss: .6f}')
x_test = torch.FloatTensor([[1, 9, 9, 8]])
y_pred = model(x_test)
y_predtensor([[-13.2952, 3.5899, 6.4243]], grad_fn=<AddmmBackward0>)# dim=1 ,두번째 차원(열방향) 적용
#
y_prob =nn.Softmax(1)(y_pred)
y_probtensor([[2.5770e-09, 5.5491e-02, 9.4451e-01]], grad_fn=<SoftmaxBackward0>)y_prob[0][0]tensor(2.5770e-09, grad_fn=<SelectBackward0>)print(f'0번 클래스의 확률: {y_prob[0][0]: .2f}')
print(f'1번 클래스의 확률: {y_prob[0][1]: .2f}')
print(f'2번 클래스의 확률: {y_prob[0][2]: .2f}')0번 클래스의 확률: 0.00
1번 클래스의 확률: 0.06
2번 클래스의 확률: 0.94
torch.argmax(y_prob,axis=1)tensor([2])
'인공지능 > 딥러닝' 카테고리의 다른 글
| Multi-class Weather Dataset (0) | 2025.03.03 |
|---|---|
| 딥러닝: 퍼셉트론과 다층 퍼셉트론 (0) | 2025.03.03 |
| 손글씨 데이터셋 (0) | 2025.02.18 |
| 파이토치로 구현한 선형 회귀 (0) | 2025.01.29 |
| 인공지능과 머신러닝, 딥러닝 (2) | 2025.01.29 |



