데이터 전처리
스타벅스
전 포스팅에서 저장한 csv파일 가져오기
df_starbucks = pd.read_csv('/본인의 구글드라이브 경로/starbucks_seoul.csv')
df_starbucks컬럼명은 보기 쉽게 한글로 변경
df_starbucks = df_starbucks.set_axis(['지점명', '지점주소', '지점위도', '지점경도'], axis=1).reset_index(drop=True)
df_starbucks
소상공인시장 진흥공단
https://hyunji00pj.tistory.com/77
소상공인시장진흥공단_상가정보 데이터셋
1. 공공데이터공공데이터(data.go.kr)는 대한민국 정부에서 운영하는 공공데이터 포털로, 공공기관이 보유한 다양한 데이터를 국민과 기업, 개발자 등에게 개방하여 활용할 수 있도록 제공하는 플
hyunji00pj.tistory.com
위 포스팅에서 사용한 상가정보 데이터 셋을 사용하여 '이디야', '올리브영', '컴포즈커피', '빽다방', '메가커피', '메가엠지씨'라는 이름의 카페의 위치와 스타벅스의 위치를 분석해서 아래 포스팅의 내용에 이어서 커피 프랜차이즈의 입점 전략을 분석해보려한다.
https://hyunji00pj.tistory.com/79
커피 프랜차이즈의 입점전략 - 스타벅스 정보 크롤링
스타벅스 "커피가 아닌 '공간'을 판매한다"https://kid.chosun.com/site/data/html_dir/2022/06/02/2022060202963.html 선택의 법칙… 스타벅스 옆엔 이디야가 있다?" data-og-description=" " data-og-host="kid.chosun.com" data-og-sour
hyunji00pj.tistory.com
상가정보 가져오기
df = pd.read_csv('/본인의 구글드라이브 경로/소상공인시장진흥공단_상가(상권)정보_서울_202409.csv', low_memory=False)
df데이터 info확인하기
df.info()
분석할 카페 변수에 저장
shop = ['이디야', '올리브영', '컴포즈커피', '빽다방', '메가커피', '메가엠지씨']데이터를 분석하다보니 메가커피가 너무 적게 나와서 확인해보니 메가커피와 메가엠지씨로 나누어져있다는 것을 확인했다.
df[df['상호명'].str.contains('메가엠지씨',case=False,na=False)]
df[df['상호명'].str.contains('메가커피',case=False,na=False)]
해서 메가커피와 메가 엠지씨처리로 두 데이터 모두 나오게해서 데이터 프레임을 확인해 보았다
df[df['상호명'].str.contains('메가커피|메가엠지씨',case=False,na=False)] # | : or 처리로 메가랑 메가엠지씨 둘다 나오게 함데이터 분석 도중 실수해도 복구할 수 있도록 데이퍼 프레임 카피본으로 작업을 한다
df_shop = df.copy()
#shop = ['이디야', '올리브영', '컴포즈커피', '빽다방', '메가커피', '메가엠지씨']
# 이디야|올리브영|컴포즈커피|빽다방|메가커피|메가엠지씨
#extract() : 특정 문자열을 포함하고 있으면 그 문자열을 반환하고, 포함하지 않으면 NaN을 반환
#extract('이디야') # 이디야 역삼점 -> 이디야 # 바나프레소 역삼점 -> NaN
df_shop['상호명'] = df_shop['상호명'].str.extract('({})'.format('|'.join(shop)))
df_shop['상호명']extract()
- df_shop 데이터프레임의 상호명 열에서, 특정 상호명(이디야, 올리브영, 컴포즈커피 등)이 포함된 경우 해당 상호명을 추출.
- 포함되지 않은 경우에는 NaN을 반환.
join()
shop 리스트의 요소들을 |(OR) 연산자로 연결하여 정규식 패턴을 만듭니다.
- 결과: '이디야|올리브영|컴포즈커피|빽다방|메가커피|메가엠지씨'
- 이 정규식은 문자열에서 "이디야", "올리브영", "컴포즈커피", ... 중 하나를 포함하는지 확인합니다.
str.extract()
- : 문자열 데이터에서 특정 패턴에 맞는 값을 추출.
- 정규식 '({})'.format('|'.join(shop)):
- 정규식 결과: '이디야|올리브영|컴포즈커피|빽다방|메가커피|메가엠지씨'
- 괄호 ()는 정규식에서 캡처 그룹을 의미하며, str.extract()는 이 그룹에 해당하는 텍스트를 추출합니다.
- 예:
- 이디야 역삼점 → 이디야
- 바나프레소 역삼점 → NaN
- 결과:
- 상호명 열에서 지정된 상호명이 포함된 경우, 상호명만 남기고 나머지는 제거합니다.
- 포함되지 않은 경우에는 NaN이 저장됩니다.

미리정의 해둔 shop변수를 사용하여 join으로 정규식 패턴을 만들어 str.extract() 사용해 상호명 열에서
shop변수에 담긴 상호명이 포함되면 상호명을 반환하고 포함되지 않으면 NaN을 반환하도록 만들었다
df_shop = df_shop[df_shop['상호명'].notna()]['상호명']
df_shop이제 NaN이 아닌 값만 필터링 하여 해당 열을 반환하도록 해서 미리 정의해둔 점포 명을 포함한 값만 반환하도록 한다

df_shop.info()
처리 후 다시 데이터프레임의 info값을 확인해보았다 총 2179개로 데이터가 많이 줄어들었다
df_shop = df_shop.dropna(subset=['상호명']).iloc[:, [0, 1, 14, 37, 38]].reset_index(drop=True)
df_shop
info로 확인했을 때에 있던 결측값 (NaN)값을 제거하고 상가업소번호와 상호명 경도 위도만 추출한다
결측지 값을 제거했으므로 데이터프레임의 인덱스는 리셋해서 새로운 데이터 프레임을 반환하도록 하였다
# 상호명에서 "메가엠지씨"를 "메가커피"로 변경
df_shop['상호명'] = df_shop['상호명'].str.replace('메가엠지씨', '메가커피', regex=False) #regex=False : 정규식 안씀
df_shop
상호명에서 메가엠지씨를 메가커피로 변경하여 통일 시켜 주었다
df_shop[df_shop['상호명'].str.contains('메가엠지씨', na=False)]
혹시나 결측지가 더 있는지 한번더 확인 하였다 결측지는 더이상 없다.
print(df_shop.shape)
print(df_starbucks.shape)
#(2179, 5)
#(630, 4)shape로 두 데이터프레임의 행과 열을 확인하였다
스타벅스 데이터프레임과 상가 데이터프레임 합치기
두 데이터프레임 df_shop과 df_starbucks의 교차 결합(Cartesian product)으로 새로운 데이터프레임 df_cross를 생성한다.
df_cross = df_shop.merge(df_starbucks, how='cross')
df_cross
하버사인 공식
Haversine 공식은 구체(구면) 위의 두 점(위도와 경도로 표시됨) 사이의 최단 거리(대원 거리, great-circle distance)를 계산하는 방법입니다. 이 공식은 GPS 좌표(위도와 경도)를 활용하여 지구 표면 위의 거리 계산에 널리 사용됩니다.

주요 특징
- 이 공식을 통해 두 점 간의 직선 거리를 미터(m), 킬로미터(km) 등 단위로 구할 수 있습니다.
- 거리 계산에서 지구의 곡률을 고려하기 때문에 정확한 결과를 제공합니다.
haversine 라이브러리: 하버사인 공식을 간단히 구현할 수 있는 Python 라이브러리설치
- 설치: !pip install haversine
- 임포트: from haversine import haversine
!pip install haversine
from haversine import haversine거리 계산 및 새로운 열 추가
df_cross['거리'] = df_cross.apply(lambda x: haversine([x['위도'], x['경도']], [x['지점위도'], x['지점경도']], unit='m'), axis=1)
df_cross
- df_cross.apply():
- 데이터프레임의 각 행(row)에 대해 함수를 적용합니다.
- axis=1은 각 행에 대해 적용함을 의미합니다.
- haversine([x['위도'], x['경도']], [x['지점위도'], x['지점경도']], unit='m'):
- 두 지점의 위도와 경도 데이터를 리스트 형태로 전달합니다.
- unit='m': 결과를 미터 단위로 반환합니다.
- 예:
- 지점 1: [37.5665, 126.9780] (서울)
- 지점 2: [37.5671, 126.9805] (근처)
- 결과: 약 200m
- 결과 저장:
- 계산된 거리를 df_cross 데이터프레임의 새로운 열 거리에 저장합니다.
개별 매장과 스타벅스와의 최소거리
# 개별 매장과 스타벅스와의 최소거리
df_dis = df_cross.groupby(['상가업소번호','상호명'])['거리'].min().reset_index()
df_dis

개별 매장과 스타벅스와의 최소거리를 구하여 정말 스타벅스 근처에 매장을 만드는 전략이 증명되는지 확인해본다
최소 거리만 봐서는 알수없으므로 평균거리도 구해보도록 하겠다
# 각 프렌차이즈 별 스타벅스와의 평균 거리
df_dis.groupby('상호명')['거리'].mean()
# agg() : 다중 집계작업을 간단하게 해주는 함수
df_dis.groupby('상호명')['거리'].agg(['mean','count'])이 코드는 pandas의 groupby와 agg 메서드를 사용하여, 데이터프레임을 상호명(상호명)을 기준으로 그룹화하고, 거리 열에 대해 여러 통계 집계 작업을 수행합니다. 결과적으로 상호명별로 평균 거리(mean)와 행 개수(count)를 계산하여 새로운 데이터프레임을 생성합니다.

# 거리를 입력하면 프랜차이즈 별 스타벅스와의 평균 거리와 매장 개수를 출력하는 함수
def distance(x):
dis = df_dis['거리'] <= x
return df_dis[dis].groupby('상호명')['거리'].agg(['mean','count'])이 함수는 특정 거리 값 x를 입력하면, df_dis 데이터프레임에서 해당 거리 이하에 있는 프랜차이즈 별로 스타벅스와의 평균 거리(mean)와 매장 개수(count)를 출력합니다.
distance(100)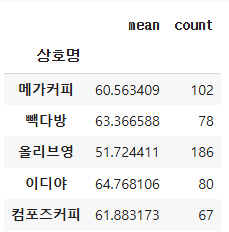
이렇게 여러 메서드와 함수를 통해서 스타벅스와 타 매장간의 거리를 비교해보니 정말 스타벅스와 아주 가까운 거리에 있다는 것을 알수 있었다
커피 프랜차이즈의 입점전략 - 시각화
pandasecharts 설치: pandas 데이터프레임을 기반으로 ECharts 그래프를 쉽게 생성할 수 있도록 도와주는 라이브러리
!pip install pandasecharts
df_100 변수에 스타벅스와 100m이내에 위치한 프랜차이즈별 평균 거리와 매장 개수가 포함된 데이터프레임 담기
df_100 = distance(100).reset_index()
df_100
IPython 임포트: Jupyter Notebook 환경에서 그래프를 올바르게 표시하기 위해 사용됩니다.
pandasecharts의 echart 함수 임포트:
import IPython
from pandasecharts import echart- echart는 pandas 데이터프레임을 기반으로 ECharts 시각화를 생성하는 함수입니다.
- 쉽게 바(bar) 차트, 선(line) 차트, 원(pie) 차트 등을 만들 수 있습니다.
1. 100m 이내 매장을 원형 차트로 시각화
df_100.echart.pie(x='상호명',y='count',figsize=(600,400),
radius=['20%','60%'],label_opts={'position':'outer'},
title='커피프랜차이즈의 입점전략은 과연 스타벅스 옆인가?',
legend_opts={'pos_right':'0%','orient':'vertical'},
subtitle='100m 이내 매장수', init_opts={'bg_color': 'white'}).render()
IPython.display.HTML(filename='render.html')
1.1 df_100 데이터
- df_100은 스타벅스에서 100m 이내에 위치한 프랜차이즈별 매장 개수를 포함하는 데이터프레임입니다.
- 열 설명:
- 상호명: 프랜차이즈 이름.
- count: 100m 이내 매장의 개수.
1.2 pie() 메서드
- pie(): 데이터프레임에서 원형 차트를 생성합니다.
- 주요 매개변수:
- x='상호명': 원형 차트에서 각 섹션의 레이블로 사용할 열.
- y='count': 원형 차트에서 각 섹션의 크기를 결정하는 값.
1.3 그래프 설정
- figsize=(600,400): 차트 크기를 600x400 픽셀로 설정.
- radius=['20%', '60%']: 차트의 안쪽과 바깥쪽 반지름 비율을 설정.
- 20%: 안쪽 반지름.
- 60%: 바깥쪽 반지름.
- label_opts={'position':'outer'}: 섹션 레이블을 원형 차트 밖에 배치.
- title 및 subtitle:
- 차트 제목: '커피프랜차이즈의 입점전략은 과연 스타벅스 옆인가?'.
- 부제목: '100m 이내 매장수'.
- legend_opts:
- pos_right='0%': 범례를 오른쪽 끝에 배치.
- orient='vertical': 범례를 세로로 정렬.
- init_opts:
- bg_color='white': 차트 배경색을 흰색으로 설정.
1.4 render()
- render(): 차트를 HTML 파일로 저장합니다.
- 파일명은 기본적으로 'render.html'로 저장됩니다.
1.5 결과 HTML 표시
- 생성된 HTML 파일을 코랩 환경에 바로 표시.
2. Timeline을 이용한 거리별 비교
from pyecharts.charts import Timeline, Grid
#Timeline :
tl = Timeline({'width':'600px', 'height':'400px'})
for i in [1000, 100, 50, 30]:
df_d = distance(i).reset_index()
pie1 = df_d.echart.pie(x='상호명', y='count', figsize=(600, 400),
radius=['20%', '60%'], label_opts={'position':'outer'},
title='커피 프렌차이즈의 입점전략은 과연 스타벅스 옆인가?',
legend_opts={'pos_right':'0%', 'orient':'vertical'},
subtitle='{}m 이내 매장수'.format(i), init_opts={'bg_color': 'white'})
tl.add(pie1, '{}m'.format(i)).render()
IPython.display.HTML(filename='render.html')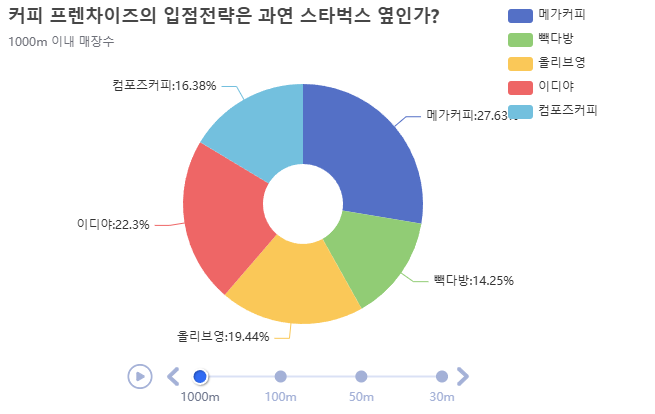
2.1 Timeline 생성
tl = Timeline({'width':'600px', 'height':'400px'})- Timeline: 시간 축 기반의 시각화를 생성하는 pyecharts 객체입니다.
- 주요 매개변수:
- width: 차트 너비 (600px).
- height: 차트 높이 (400px).
2.2 거리별 데이터 생성
for i in [1000, 100, 50, 30]: df_d = distance(i).reset_index()- distance(i):
- i 거리 이내에 위치한 프랜차이즈 매장을 필터링한 데이터프레임 생성.
- reset_index():
- 데이터프레임의 인덱스를 초기화.
2.3 거리별 원형 차트 생성
pie1 = df_d.echart.pie(x='상호명', y='count', figsize=(600, 400),
radius=['20%', '60%'], label_opts={'position':'outer'},
title='커피 프렌차이즈의 입점전략은 과연 스타벅스 옆인가?',
legend_opts={'pos_right':'0%', 'orient':'vertical'},
subtitle='{}m 이내 매장수'.format(i), init_opts={'bg_color': 'white'})- 원형 차트 생성은 앞서 설명한 방식과 동일하나, subtitle이 거리(i)에 따라 동적으로 생성됩니다.
2.4 차트를 Timeline에 추가
tl.add(pie1, '{}m'.format(i))- add(): Timeline 객체에 차트를 추가.
- pie1: 생성된 원형 차트.
- '{}m'.format(i):
- 차트의 시간 축 레이블로 사용됩니다.
- 예: 1000m, 100m, 50m, 30m.
2.5 결과 HTML 표시
tl.render() IPython.display.HTML(filename='render.html')- Timeline 차트를 HTML로 저장하고 표시.
결론: 스타벅스는 프랜차이즈 입점 전략의 핵심 요소인가?
분석 결과, 스타벅스 근처(특히 100m 이내)에 위치한 프랜차이즈 매장이 상당히 많음을 확인할 수 있었습니다.
이디야, 메가커피, 빽다방과 같은 커피 프랜차이즈뿐만 아니라, 올리브영과 같은 생활 편의 매장도 스타벅스 인근에 집중되는 경향이 있었습니다.
이를 통해 다음과 같은 인사이트를 얻을 수 있습니다.
✅ 스타벅스는 단순한 커피 브랜드가 아닌, ‘핫스팟’ 역할을 한다
- 스타벅스가 입점한 지역은 보행량이 많고 상권이 활성화된 지역일 가능성이 큽니다.
- 스타벅스 근처에 다른 프랜차이즈가 함께 입점함으로써 시너지 효과를 노릴 수 있습니다.
✅ 커피 프랜차이즈의 입점 전략: ‘스타벅스 따라가기’?
- 경쟁 브랜드인 이디야, 메가커피, 컴포즈커피 등은 스타벅스 근처에 매장을 배치하는 전략을 취하는 것으로 보입니다.
- 스타벅스를 방문하는 유동 고객층을 공략해 ‘대체재’ 역할을 하거나, 스타벅스가 미처 감당하지 못하는 고객층(가성비 고객)을 타겟으로 합니다.
✅ 거리별 분석을 통해 본 입점 패턴 차이
- 50m 이내에는 소수의 매장만 존재하며, 스타벅스와 바로 경쟁하기보다는 **조금 떨어진 거리(100m~200m)**에서 대체재 역할을 하는 패턴이 보입니다.
'인공지능 > 데이터분석' 카테고리의 다른 글
| 머신러닝 (2) | 2025.01.29 |
|---|---|
| 인공지능과 머신러닝, 딥러닝 (2) | 2025.01.29 |
| 커피 프랜차이즈의 입점전략 - 스타벅스 정보 크롤링 (0) | 2025.01.24 |
| 서울시 공공자전거 실시간 대여정보 (0) | 2025.01.24 |
| 소상공인시장진흥공단_상가정보 데이터셋 (4) | 2025.01.17 |



